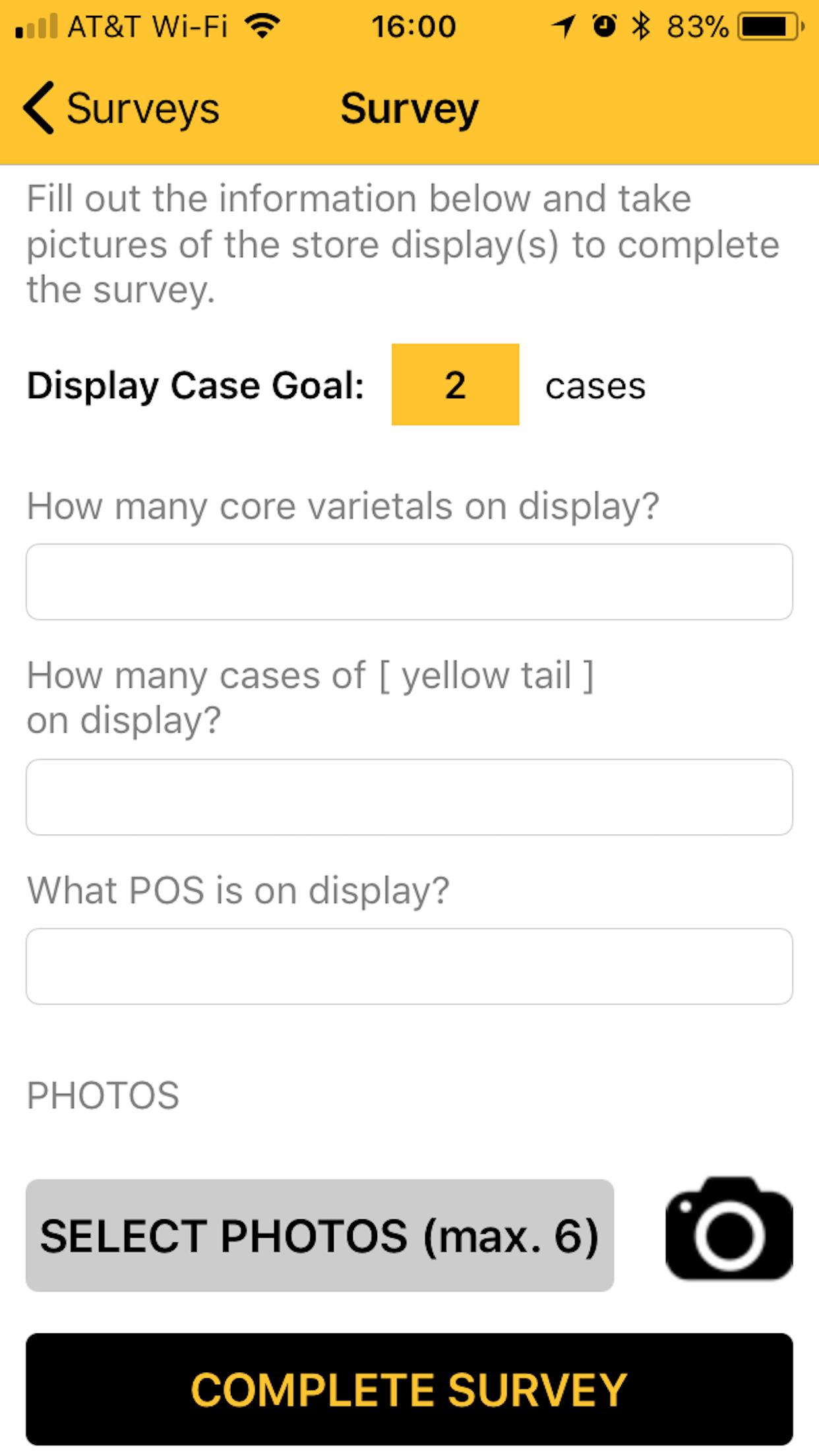
We guide large, medium, and small enterprises toward the right solution. From architects and technologists to designers and UI experts, the Chateaux Team has the depth and breadth of expertise to successfully plan and deliver your project. Our collective strength, skill, and knowledge across industries and technologies come from years of dedicated service.
Our Expertise
What Our Clients Are Saying
Chateaux did a great job for us! Ken and his team were able to develop flexible reports that received a tremendous amount of positive feedback from our user community.
Over the last few years since we engaged Chateaux, we have been extremely impressed with their capabilities and ability to execute. Chateaux’s team of Architects, Designers, and Developers has been completely instrumental to our business and technology success!
I would just like to thank you for the tremendous effort you have put towards Heineken. You and your team have met the challenges set forth in a manner that is quite commendable. I truly feel that Chateaux has added a tremendous amount of value in the overall development of reporting, data development, data strategy, and overall business planning development.
Chateaux has proven to be an invaluable resource. They have brought me expertise at the strategic level, in helping lay out an Enterprise Architecture in these areas. I highly recommend this company for your Enterprise Architecture, Business Intelligence and Data Architecture needs.
Chateaux won with flying colors because of their long history working with BusinessObjects, dating back to before it was acquired by SAP. I would highly recommend the Chateaux team for any SAP endeavors; the entire experience was unsurpassed by any other vendor we have worked with, from installation, to optimization, to training.
Chateaux’s visionary enterprise and information architecture will be the integrating foundation for portals and future applications for the next few years.
Chateaux once again proved their ability to conceptualize the solution and deliver it on time and on budget.
I truly enjoyed working with Chateaux on the Broker Portal project. The communication, dedication, and commitment to results is impeccable! The many demos for the various individuals, the patience in explaining and answering questions, the countless hours dedicated to meet deployment demands, the many code updates from testing efforts & other changes – all examples of an outstanding employee who is committed to results!
There are three points regarding Chateaux that I’d really like to highlight: their commitment to a successful project; their level of expertise and ability to overcome obstacles; and their professionalism.
Don Floyd and the group at Chateaux brought Lean Architecture to light for us. They educated a wide range of people and changed the dialog within the IT group and across the business.
The solution is pretty amazing; it just runs, and we don’t need to maintain it, which was one of our main goals. Chateaux provided a solid design followed by a successful implementation that met all of our needs and has helped make BI more affordable for us.
Chateaux did a great job of understanding our overall needs, designing solutions, and implementing those solutions to support our growing business. Their professionalism and ability to work with both the business and technology folks has been very impressive! We look forward to working with the Chateaux team in a variety of capacities that will help us to increase user productivity, standardize our business processes, and implement governance to reduce risk.
Chateaux did a great job with our analytics solutions, not only providing great support but also designing innovative solutions to enhance our executive dashboards.
Featured Projects